This paper is concerned with STV elections in which there are no 'party' affiliations. Hence the voting patterns are different from those which applied in the Irish elections analysed in the first reference. The identity of the actual council elections used for this study is not stated here, since this is irrelevant and could detract from the conclusions which are thought to be relevant for all elections for several seats in which there are no parties involved.
The program used in this study works as follows. The program computes transfer rates from A to B if candidate A was eliminated or had a surplus to transfer (and B was available for transfers). If no such transfer occurred, then an estimate is used based upon the first preferences for B.
Ballot papers are now constructed using a random number generator with an exact match for the first preferences. This set is then used as the starting point of an iterative process, working stage by stage, to obtain a very close fit to the actual result sheet. The program cannot necessarily obtain a perfect match when transfers of surpluses are involved. Experiments showed that the starting position which was dependent upon the seeds for the random number generator did not have a large effect on the accuracy of the final fit to the actual election.
10 AB 5 BCD 6 BAD 6 CDA 1 C 8 DABThe result sheet from these ballot papers using Newland-Britton is:
Stage 1 Stage 2 Stage 3
A 10 10 0
B 11 11 21
C 7 0 0
D 8 14 14
Non-T 0 1 1
Since we are concerned with a council election without parties, we consider
each candidate in the same way. We can judge the overall popularity of each
candidate from the first preference votes. We now construct a matrix to
represent the probability of X being followed by Y in any preference (X
could clearly be the last preference given, so Y is allowed to be the
Non-Transferable option). For instance, given candidate D, then the
preference specified after D is assumed to be A, B or C in the ratio 10:11:7
(since these are the ratios of the votes on the first preferences).
We can make a better estimate of the transfer probabilities, since we do have a limited amount of information from the result sheet. In this case, for stage 2 in which C is eliminated, we know that the next preferences were either D or non- transferable in the ratio 6:1, respectively. Hence, we can adjust our matrix accordingly. For stage 3, in which A is eliminated, the transfers were entirely to B, but the papers could have had a preference to C which would have been ignored. This clearly reflects the adjustments made to the matrix. The final matrix, based upon one hundredths of a vote, in this case becomes:
TO
FROM NT A B C D
STRT - 278 306 194 222
A 0 - 1000 194 222
B 0 278 - 194 222
C 143 278 306 - 857
D 0 278 306 194 -
The program now computes a trial set of ballot papers with an exact match on
the first preferences, but using a pseudo-random number generator and the
above matrix to produce the remaining preferences. Finally, adjustments are
made to the papers to obtain a better match to the result sheet. The root
mean square error is computed over the entries in the result sheet, which
gives 0 in this case for the 3×5 entries, since we have a perfect match.
The ballot papers produced in this case (which depends upon the seeds used for the random-number generator) were:
2 ABCD 7 ABDC 1 ACBD 3 BADC 4 BCDA 2 BDAC 1 BDC 1 BDCA 1 C 2 CDAB 4 CDBA 1 DABC 4 DBAC 1 DBCA 1 DCAB 1 DCBAThere are clearly many differences between the initial ballot papers and the above. However, since there are 64 ways of voting, it is quite unlikely that 10 ballot papers would be identical as with the initial papers (and in this sense, the final set must be regarded as more likely than the starting set). The construction method in this case gives very few papers with incomplete preferences, since the result sheet had few non-transferables.
The first row in Table 2 gives the number of candidates which were never elected in any of the 100 elections, called no-hopers. It would seem that this is not an unreasonable definition of those that have no chance of election, since we know that the number of first-preference votes is not always a good indication.
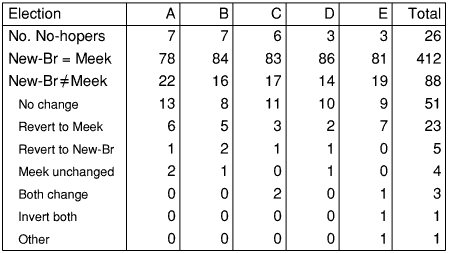
The 88 elections in which Newland-Britton/Meek gave a different result were now re-run with the no-hopers eliminated. The results of this are recorded in Table 2 in the rows with indented titles. In all but one case, the difference between the two algorithms was just one candidate. However, the result of the re-runs is somewhat confusing except for the simple case in which the elimination of the no-hopers makes no difference. The result in the table are classified as follows:
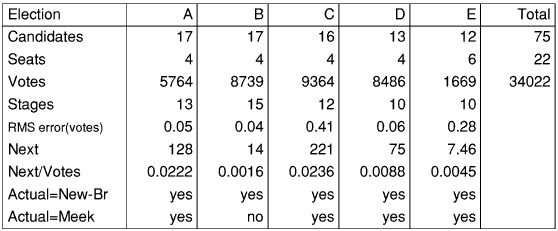
The first result from this study is that Newland-Britton and Meek produce a different result for about 4% of the seats. The observed rate for the Irish elections in 1969 was 2.8% (3 out of 143) and for 1973 was 4.9% (7 out of 143). The difference between 1969 and 1973 is due to a decline in the party voting and hence is consistent with a figure of 4% given in this study.
Does a difference of 4% matter between two STV algorithms? Obviously, it is reasonable to say this is insignificant against a difference of around 30% when STV is compared to First Past The Post. On the other hand, for the Electoral Reform Society, it is surely unsatisfactory to have such differences. Unfortunately, resolving this issue, as we are all aware, is not easy.
The remaining result is that Meek has more indicative cases in its support than Newland-Britton by about 5 to 1 in the above experiment. Does this matter? Surely, a key advantage of STV is that candidates can enter without upsetting the result if they have no realistic chance of being elected. Providing other hurdles for candidates seems against the spirit of democracy.